<!–The echo: false option disables the printing of code (only output displayed). <!– CNTR + ALT + I to create new code chunks
PROJECT CAFE
I’m using the ../../../../data/coffee_survey.csv and below is my analysis. Let’s take a closer look!
This is a survey of 3790 consumers who were asked 43 questions about their coffee preferences
X age cups where_drink
1 1 <18 years old 3 At home, At the office, At a cafe
2 2 >65 years old 3 At the office, At a cafe
3 3 25-34 years old 1 At home, At the office, On the go
4 4 18-24 years old 2 At the office
5 5 45-54 years old 2 At home, At the office, At a cafe, On the go
6 6 >65 years old 1 At home
purchase_other favourite favorite_specify
1 <NA> Pourover <NA>
2 <NA> Cortado <NA>
3 <NA> Regular drip coffee <NA>
4 <NA> Iced coffee <NA>
5 <NA> Regular drip coffee <NA>
6 <NA> Regular drip coffee <NA>
additions
1 No - just black, Milk, dairy alternative, or coffee creamer
2 No - just black
3 Milk, dairy alternative, or coffee creamer, Sugar or sweetener
4 Milk, dairy alternative, or coffee creamer
5 No - just black
6 No - just black
additions_other sweetener style strength
1 <NA> <NA> Bright Medium
2 <NA> <NA> Fruity Somewhat strong
3 <NA> Granulated Sugar, Brown Sugar Sweet Somewhat strong
4 <NA> <NA> Nutty Somewhat strong
5 <NA> <NA> Floral Medium
6 <NA> <NA> Full Bodied Somewhat strong
roast_level caffeine expertise coffee_a_bitterness coffee_a_acidity
1 Light Full caffeine 10 1 1
2 Blonde Full caffeine 7 3 3
3 Medium Full caffeine 6 3 3
4 Nordic Full caffeine 4 4 4
5 Light Full caffeine 8 3 3
6 Dark <NA> 2 3 3
coffee_a_personal_preference coffee_b_bitterness coffee_b_acidity
1 1 1 1
2 3 3 3
3 3 3 3
4 4 4 4
5 4 3 3
6 3 3 3
coffee_b_personal_preference coffee_c_bitterness coffee_c_acidity
1 1 1 1
2 3 3 3
3 3 3 3
4 4 NA 4
5 5 4 3
6 3 4 3
coffee_c_personal_preference coffee_d_bitterness coffee_d_acidity
1 1 1 1
2 3 3 3
3 3 3 3
4 4 4 4
5 3 5 2
6 NA 4 3
coffee_d_personal_preference prefer_abc prefer_ad prefer_overall
1 1 Coffee A Coffee D Coffee B
2 3 Coffee C Coffee D Coffee D
3 3 Coffee A Coffee A Coffee B
4 4 <NA> Coffee D Coffee A
5 3 Coffee B Coffee A Coffee B
6 4 Coffee C Coffee D Coffee C
wfh total_spend know_source most_paid most_willing
1 I primarily work from home >$100 <NA> <NA> <NA>
2 <NA> <NA> <NA> <NA> <NA>
3 I primarily work from home $40-$60 <NA> <NA> <NA>
4 <NA> <NA> <NA> <NA> <NA>
5 I primarily work from home $20-$40 Yes $4-$6 $8-$10
6 <NA> <NA> <NA> <NA> <NA>
value_cafe spent_equipment value_equipment gender
1 <NA> <NA> <NA> Other (please specify)
2 <NA> <NA> <NA> <NA>
3 <NA> <NA> <NA> Female
4 <NA> <NA> <NA> <NA>
5 No $500-$1000 Yes Male
6 <NA> <NA> <NA> <NA>
education_level employment_status number_children political_affiliation
1 Bachelor's degree Employed full-time More than 3 Democrat
2 <NA> <NA> <NA> <NA>
3 Bachelor's degree Employed full-time None Democrat
4 <NA> <NA> <NA> <NA>
5 Master's degree Employed full-time 2 No affiliation
6 <NA> <NA> <NA> <NA>
'data.frame': 3790 obs. of 43 variables:
$ X : int 1 2 3 4 5 6 7 8 9 10 ...
$ age : chr "<18 years old" ">65 years old" "25-34 years old" "18-24 years old" ...
$ cups : chr "3" "3" "1" "2" ...
$ where_drink : chr "At home, At the office, At a cafe" "At the office, At a cafe" "At home, At the office, On the go" "At the office" ...
$ purchase_other : chr NA NA NA NA ...
$ favourite : chr "Pourover" "Cortado" "Regular drip coffee" "Iced coffee" ...
$ favorite_specify : chr NA NA NA NA ...
$ additions : chr "No - just black, Milk, dairy alternative, or coffee creamer" "No - just black" "Milk, dairy alternative, or coffee creamer, Sugar or sweetener" "Milk, dairy alternative, or coffee creamer" ...
$ additions_other : chr NA NA NA NA ...
$ sweetener : chr NA NA "Granulated Sugar, Brown Sugar" NA ...
$ style : chr "Bright" "Fruity" "Sweet" "Nutty" ...
$ strength : chr "Medium" "Somewhat strong" "Somewhat strong" "Somewhat strong" ...
$ roast_level : chr "Light" "Blonde" "Medium" "Nordic" ...
$ caffeine : chr "Full caffeine" "Full caffeine" "Full caffeine" "Full caffeine" ...
$ expertise : int 10 7 6 4 8 2 10 6 7 8 ...
$ coffee_a_bitterness : int 1 3 3 4 3 3 1 1 2 3 ...
$ coffee_a_acidity : int 1 3 3 4 3 3 4 4 3 3 ...
$ coffee_a_personal_preference: int 1 3 3 4 4 3 4 3 4 2 ...
$ coffee_b_bitterness : int 1 3 3 4 3 3 1 3 3 NA ...
$ coffee_b_acidity : int 1 3 3 4 3 3 4 2 2 NA ...
$ coffee_b_personal_preference: int 1 3 3 4 5 3 4 4 2 NA ...
$ coffee_c_bitterness : int 1 3 3 NA 4 4 1 3 2 NA ...
$ coffee_c_acidity : int 1 3 3 4 3 3 4 4 2 NA ...
$ coffee_c_personal_preference: int 1 3 3 4 3 NA 4 1 2 NA ...
$ coffee_d_bitterness : int 1 3 3 4 5 4 2 1 3 NA ...
$ coffee_d_acidity : int 1 3 3 4 2 3 4 4 3 NA ...
$ coffee_d_personal_preference: int 1 3 3 4 3 4 4 5 2 NA ...
$ prefer_abc : chr "Coffee A" "Coffee C" "Coffee A" NA ...
$ prefer_ad : chr "Coffee D" "Coffee D" "Coffee A" "Coffee D" ...
$ prefer_overall : chr "Coffee B" "Coffee D" "Coffee B" "Coffee A" ...
$ wfh : chr "I primarily work from home" NA "I primarily work from home" NA ...
$ total_spend : chr ">$100" NA "$40-$60" NA ...
$ know_source : chr NA NA NA NA ...
$ most_paid : chr NA NA NA NA ...
$ most_willing : chr NA NA NA NA ...
$ value_cafe : chr NA NA NA NA ...
$ spent_equipment : chr NA NA NA NA ...
$ value_equipment : chr NA NA NA NA ...
$ gender : chr "Other (please specify)" NA "Female" NA ...
$ education_level : chr "Bachelor's degree" NA "Bachelor's degree" NA ...
$ employment_status : chr "Employed full-time" NA "Employed full-time" NA ...
$ number_children : chr "More than 3" NA "None" NA ...
$ political_affiliation : chr "Democrat" NA "Democrat" NA ...
X age cups where_drink
Min. : 1.0 Length:3790 Length:3790 Length:3790
1st Qu.: 948.2 Class :character Class :character Class :character
Median :1895.5 Mode :character Mode :character Mode :character
Mean :1895.5
3rd Qu.:2842.8
Max. :3790.0
purchase_other favourite favorite_specify additions
Length:3790 Length:3790 Length:3790 Length:3790
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
additions_other sweetener style strength
Length:3790 Length:3790 Length:3790 Length:3790
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
roast_level caffeine expertise coffee_a_bitterness
Length:3790 Length:3790 Min. : 1.000 Min. :1.000
Class :character Class :character 1st Qu.: 5.000 1st Qu.:1.000
Mode :character Mode :character Median : 6.000 Median :2.000
Mean : 5.683 Mean :2.141
3rd Qu.: 7.000 3rd Qu.:3.000
Max. :10.000 Max. :5.000
coffee_a_acidity coffee_a_personal_preference coffee_b_bitterness
Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.:3.000 1st Qu.:2.000 1st Qu.:2.000
Median :4.000 Median :3.000 Median :3.000
Mean :3.634 Mean :3.311 Mean :3.014
3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000
Max. :5.000 Max. :5.000 Max. :5.000
NA's :18 NA's :14 NA's :20
coffee_b_acidity coffee_b_personal_preference coffee_c_bitterness
Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000
Median :2.000 Median :3.000 Median :3.000
Mean :2.223 Mean :3.067 Mean :3.072
3rd Qu.:3.000 3rd Qu.:4.000 3rd Qu.:4.000
Max. :5.000 Max. :5.000 Max. :5.000
NA's :32 NA's :28 NA's :33
coffee_c_acidity coffee_c_personal_preference coffee_d_bitterness
Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.:2.000 1st Qu.:2.000 1st Qu.:1.000
Median :2.000 Median :3.000 Median :2.000
Mean :2.366 Mean :3.066 Mean :2.162
3rd Qu.:3.000 3rd Qu.:4.000 3rd Qu.:3.000
Max. :5.000 Max. :5.000 Max. :5.000
NA's :45 NA's :33 NA's :29
coffee_d_acidity coffee_d_personal_preference prefer_abc
Min. :1.000 Min. :1.000 Length:3790
1st Qu.:3.000 1st Qu.:2.000 Class :character
Median :4.000 Median :4.000 Mode :character
Mean :3.858 Mean :3.375
3rd Qu.:5.000 3rd Qu.:5.000
Max. :5.000 Max. :5.000
NA's :32 NA's :36
prefer_ad prefer_overall wfh total_spend
Length:3790 Length:3790 Length:3790 Length:3790
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
know_source most_paid most_willing value_cafe
Length:3790 Length:3790 Length:3790 Length:3790
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
spent_equipment value_equipment gender education_level
Length:3790 Length:3790 Length:3790 Length:3790
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
employment_status number_children political_affiliation
Length:3790 Length:3790 Length:3790
Class :character Class :character Class :character
Mode :character Mode :character Mode :character
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
[1] 3790
[1] 43
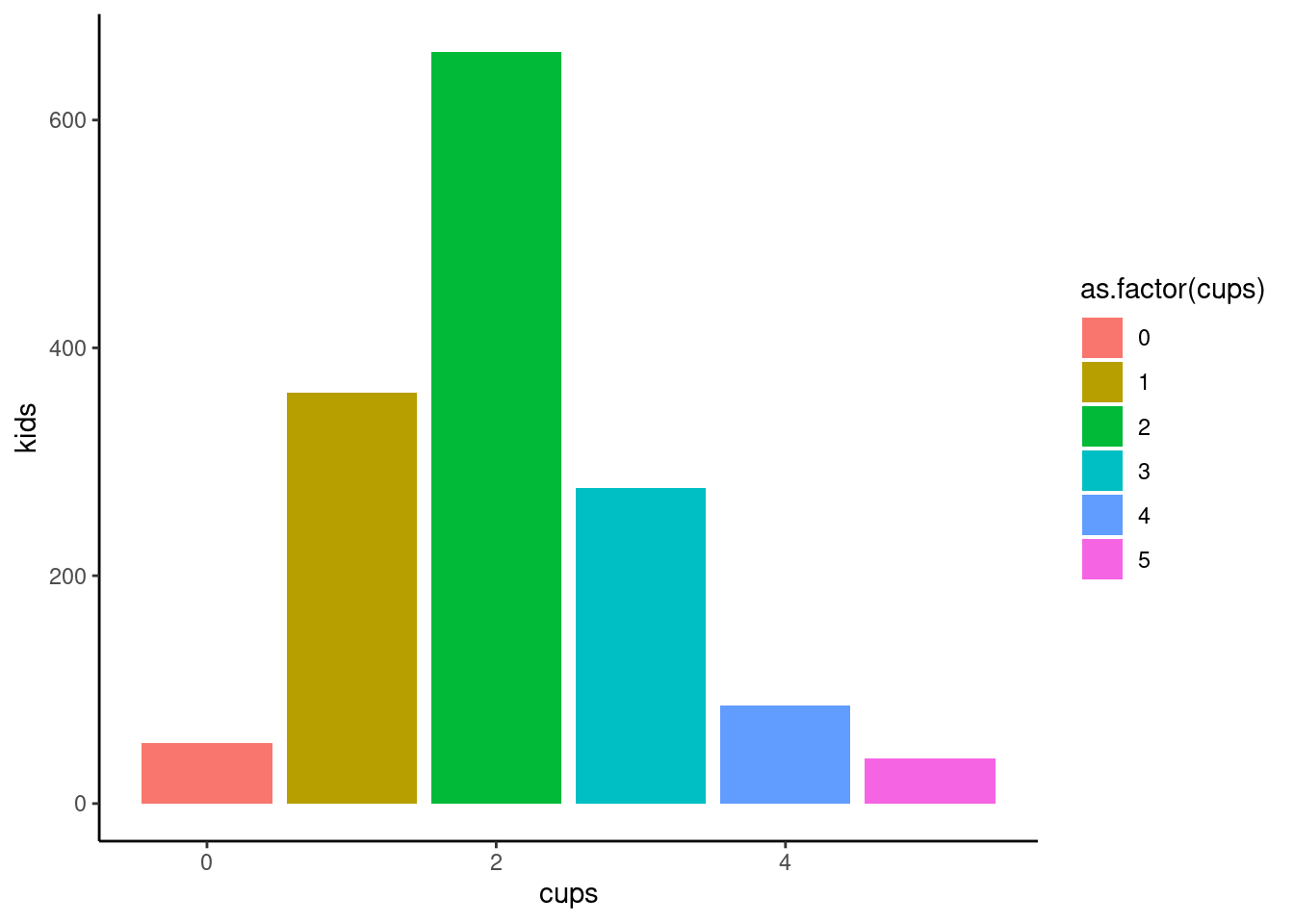
CLEANING THE CUPS (Data Cleaning)
Let’s look at a few interesting factors and remove missing values
#Removing the NA's from the variables I am interested in as a new df called "clean_cup"unique(cafe$cups)
[1] "3" "1" "2" "More than 4" "Less than 1"
[6] NA "4"
Let’s continue to make the data in a format we can use by changing the column names, replacing characters and making characters/factors into numerical data
#First change the names of the columns to make the code easier to use: politics, kids, cups, caffeineclean_cup <- clean_cup %>%rename(politics = political_affiliation)clean_cup <- clean_cup %>%rename(kids = number_children)#clean_cup$politics#unique(clean_cup$politics)#summary(clean_cup$politics)#clean_cup$kids#unique(clean_cup$kids)#summary(clean_cup$kids)#clean_cup$caffeine#unique(clean_cup$caffeine)summary(clean_cup$caffeine)
The following package(s) will be installed:
- stringr [1.6.0]
These packages will be installed into "~/tech_training/training-intensives/renv/library/linux-ubuntu-jammy/R-4.5/x86_64-pc-linux-gnu".
# Installing packages --------------------------------------------------------
- Installing stringr ... OK [linked from cache]
Successfully installed 1 package in 7.4 milliseconds.
library(stringr) #use to change characters quicklylibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ forcats 1.0.0 ✔ readr 2.1.5
✔ lubridate 1.9.4 ✔ tibble 3.2.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
#Next let's change the order of "number of cups consumed" to be ordinal/incremental#Make a smaller more manageable data frame called small_cafesmall_cafe <- clean_cup |>select("politics", "cups", "caffeine", "kids")#For number kids and cups make categorical variables numerical#Change to numbers: if its this turn to that if else leave as issmall_cafe <- small_cafe |>mutate(kids =if_else(kids =="None",true ="0",false = kids),kids =if_else(kids =="More than 3",true ="4",false = kids))#Another way to do the same thing by make it a case when this = this do this.small_cafe <- small_cafe |>mutate(kids =as.numeric(case_when(kids =="None"~"0", kids =="More than 3"~"4",.default = kids)))#Apply to the "cups" datasmall_cafe <- small_cafe |>mutate(cups =if_else(cups =="Less than 1",true ="0",false = cups),cups =if_else(cups =="More than 4",true ="5",false = cups))#Other Optionsmall_cafe <- small_cafe |>mutate(cups =as.numeric(case_when(cups =="Less than 1"~"0", cups =="More than 4"~"5",.default = cups)))#Make data numericalsmall_cafe <- small_cafe |>mutate(kids =as.numeric(kids),cups =as.numeric(cups))# if(!is.numeric(small_cafe$cups)) small_cafe$cups <- as.numeric(small_cafe$cups)class(small_cafe$cups) #santity check the class is numeric